作者:Raul Jordan
发布时间:2018年9月3日
微信公众号:蓝狐笔记
前言:哈希算法对于保证区块链网络安全很重要。为了减少哈希冲突可能性,要么提高哈希内部操作的复杂性,要么提高哈希输出的长度,寄希望于攻击者计算速度不够快。本文分析了哈希算法的历史,原理和未来,对于我们理解区块链的安全问题很有帮助。本文作者是Raul Jordan,文章来源于medium.com,由蓝狐笔记社群“李熙和”翻译。
新手在了解区块链的时候经常会接触到哈希(hash)和哈希算法(hashing algorithm)这样的概念,它们在安全方面可以说是无处不在。通过P2P运行像比特币,以太坊之类有众多节点的去中心化网络需要去信任机制和验证的高效性。
这就是说,这些系统需要想办法将信息以一种高效而简洁的方式编码,并允许其参与者能够安全而快速的进行验证。
比特币和以太坊所涉及的主要概念是“区块”,这是一种包含交易记录,时间戳以及其他元数据的数据结构。这种数据结构安全性的关键在于:它能够将大量关于全球网络状态的信息压缩成一小段信息标准,并使这一小段信息能被高效的验证,这一小段信息被称为哈希。

即使仅仅改变输入信息的一个字符也会产生一个完全不同的哈希值!
加密学上的哈希被用于各行各业,从密码储存到文件验证系统。基本思想是使用一种确定性的算法(deterministicalgorithm),这种算法能够接受一个输入并每次都产生一个长度固定的字符串。也就是说,一个相同的输入得到的永远都是相同的输出。
除了这种确定性,哈希算法还有一个特性:输入中的任何一点点的改变都会导致输出变得完全不同。
哈希算法有一个问题,就是冲突必然性(inevitability of collisions)。它的意思是:由于哈希函数输出的字符串长度一定,不同的输入有可能会产生相同的哈希值。冲突是不好的,如果一个攻击者能够故意产生冲突,他便能够把恶意的文件或者数据伪装成正确的哈希值并将其传递下去。一个好的哈希函数的目标是让冲突的发生变得几乎不可能。
计算一个哈希值不应该太过高效,因为这会让冲突的实现变得太过容易。哈希算法应该能够抵御“原像攻击(pre-image attack)”。也就是说,根据已知的哈希值找到输入值应该是极其困难的(输入值被称作原像,比如s = hash(x),根据s找到x应该是几乎不可能的)。
总结起来,一个好的哈希算法应该具备以下特征:
· 改变输入的任意一点都会产生一个完全不同的输出
· 发生冲突的可能性非常低
· 在不牺牲抵御冲突的情况下有一定的效率
攻击哈希
最初的哈希算法标准之一是MD5哈希,它被广泛的应用于文件完整性验证(校验和),同时在网络应用的数据库中用于储存哈希密码。那时它的功能还十分简单,因为不论输入如何,输出是一个固定的128位的字符串,并且它使用并不有效的多轮单向操作(one-wayoperations across several rounds)来计算确定性输出。
由于输出字符串长度较短以及操作较为简单,MD5很容易被破解并易受生日攻击(Birthday Attack)的侵扰。
什么是“生日攻击”?
你可能听说过:如果一个房间里有23个人,那么两两生日重叠的可能性就有50%,而在一个房间内如果提高到70人,那么这个概率就变成了99.9%。这就是鸽子洞原则(pigeonhole principle),如果有100只鸽子只有99个洞,那么必然有一个洞中有两只鸽子。
放在哈希算法的案例中就变成了,一个固定长度的字符串意味着一个固定的排列组合数量,因此当输入值达到一定的数量时,冲突必然会发生。

太多鸽子了!至少有一只鸽子会与另一只共用一个洞
MD5抵御冲突的能力如此之弱,以至于一个2.4GHz的奔腾处理器都能在数秒之内制造一次哈希冲突。事实上,由于MD5在较早年代的广泛应用,已经有大量的原像在线上泄漏,你甚至可以用简单的谷歌搜索来找到它们。
多样性和哈希算法的进化
开端:SHA1 & SHA2
美国国家安全局(NSA)一直都是哈希算法标准方面的先驱,他们最早提出安全哈希算法,也就是SHA1,这个算法输出的是160位固定长度的字符串。
然而,SHA1仅仅在MD5的基础上提高了输出的长度,单向操作的数量以及单向操作的复杂性,但未做任何根本改进来使其能够抵御更强大的机器,这些机器尝试不同的攻击向量。
那么我们该如何提高呢?
SHA3
在2006年,美国国家标准与技术研究所(NIST)发起了一场寻找一个与SHA2从根本上不同的替代品,让它成为新的算法标准。因此,SHA3的诞生是哈希算法伟大机制的一部分,它被称为KECCAK。
虽然名字看上去差不多,SHA3内部与之前的算法完全不同,因为它拥有海绵结构(Sponge Construct)机制。这种结构使用随机的排列组合来吸收和输出数据,同时还能为未来输入值提供随机源。
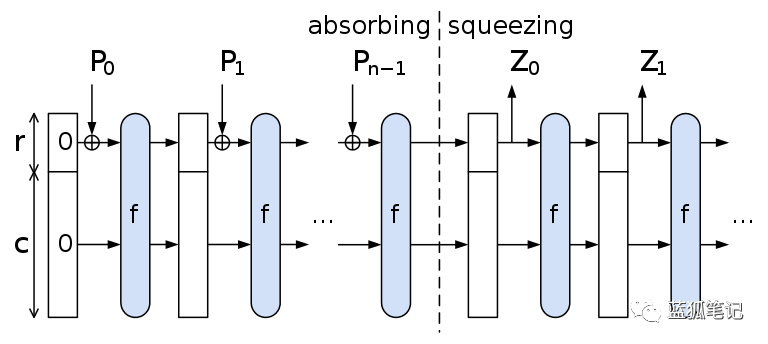
KECCAK256海绵结构作用于输入值
SHA3维持一个内部状态,使得输出信息比字符串长度长(依然能够做到对于信息的压缩),这使它克服了先前算法的局限性。它也在2015年成为了NIST的标准算法。
哈希和PoW
当哈希算法被集成到区块链协议中的时候,更老一些的比特币选择了SHA256算法,而以太坊选择了改良版的SHA3(KECCAK256)作为PoW的算法。一个在区块链PoW协议中选择哈希函数的重要标准是计算哈希值的效率。
对比特币SHA256算法的执行效率可以通过制造诸如ASICs矿机之类的专门硬件来进一步提高。这表现在矿池中ASICs的使用,并使协议趋向于计算中心化。
也就是说,PoW鼓励高效的计算群体聚合成更大的群体(矿池)从而提高我们所说的哈希算力(也就是一个机器在固定的时间间隔能够计算的哈希数量)。
以太坊,选择了改良后的SHA3,也被称作KECCAK256。此外,以太坊的PoW算法(Dagger-Hashimoto)设计成硬件内存难以计算,这从一定程度上避免了ASICs矿机的使用。
为什么比特币要使用双重SHA256?
比特币使用SHA256来转换数据的方式很有趣,它将算法在协议中连续执行了两次。注意,这并不是为了抵御生日攻击,显然如果hash(x) = hash(y) 那么也有hash(hash(x)) = hash(hash(y)),而是为了缓解长度扩展(length-extension)攻击。
从本质上说,这种攻击需要恶意攻击者知道哈希输入值的长度,在这个已知的长度上再加上一个秘密的字符串,就可以发动哈希函数内部的一部分,从而扰乱哈希函数。由于SHA256是SHA2算法家族的成员,它有这一类的短板,而比特币通过将哈希函数连续运行两次来缓解这个缺陷。
以太坊2.0和BLAKE
SHA3并不是NIST在2006年发起的那场竞赛中唯一的突破。虽然SHA3最终获胜,一个叫做BLAKE的算法紧随其后位居第二。对于以太坊2.0分片的执行,更高效的哈希算法可以说是必不可少的。
BLAKE2b哈希算法是一个在竞赛之后被高度升级优化过的版本,由于在保持高度安全性的同时拥有极高的效率(跟KECCAK256相比),这个算法也经历了较为彻底的测试。
在一个现代CPU上计算BLAKE2b实际上比KECCAK要快3倍。
哈希算法的未来
看起来无论我们做什么,要么是在(1)提高哈希函数内部操作的复杂性,要么是在(2)提高哈希输出的长度,寄希望于攻击者的计算机由于速度不够快而无法有效产生计算冲突。
我们网络的安全性目前依赖着单向操作原像的模糊性。也就是说一个哈希算法的安全目标是让任何人找到具有两个相同输出的值变得越难越好,从而使得哈希冲突的可能性尽可能的小,虽然依旧存在无限数量的可能的冲突。
那么量子计算呢?在量子计算面前哈希算法足够安全吗?
根据目前的理解,简单的回答是:安全。哈希算法将能够经受量子计算的挑战。量子计算能够破解那些诸如RSA加密问题,这些问题具有严格的底层数学结构,它们由巧妙的技巧和理论构建。而哈希算法内部构造中并没有那么正式的结构。
量子计算机确实可以加快计算非结构化问题(如哈希)的速度,但是到最后,量子计算机发起攻击的方式依然是暴力破解,和传统的计算机并没有什么不同。
不论我们选择什么算法,显然我们都在驶向一个计算更高效的未来,我们必须尽全力挑选最好的工具并经得起时间的考验。
——
风险警示:蓝狐笔记所有文章都不构成投资推荐,投资有风险,投资应该考虑个人风险承受能力,建议对项目进行深入考察,慎重做好自己的投资决策。