作者:Mark(周邺飞 : 币创技术副总裁 、DACA区块链协会讲师、区块链技术专家)
时间:2016年11月8日
来源:http://www.8BTC.com/blockchain-tech-mining

上篇讲算法演进,本篇讲挖矿演进,挖矿是作算法运算的过程,从计算机和代码的角度来说,是反复执行Hash函数并检测执行结果的具体过程。与讨论算法一样,挖矿也是在采用POW共识机制前提下讨论。
大家已经非常清楚挖矿是由最开始的CPU挖矿,过度到GPU挖矿,最终演化到当前的ASIC(专业矿机)挖矿时代,本篇解析其中的逻辑设计和技术实现。挖矿的演进是硬件的演进过程,同时也是软件的演进过程,尤其是软硬件对接协议的改进过程,因此本文直接将与挖矿有关的几个核心协议作为小标题,一步步深入讨论。
在复查文章时我发现“矿工”一词用的比较模糊,这种情况在英文文献也差不多,日常交流中一般指拥有挖矿机器的人,本篇着眼于区块链,挖矿的程序或者机器都统称矿工(Miner)。
MINING
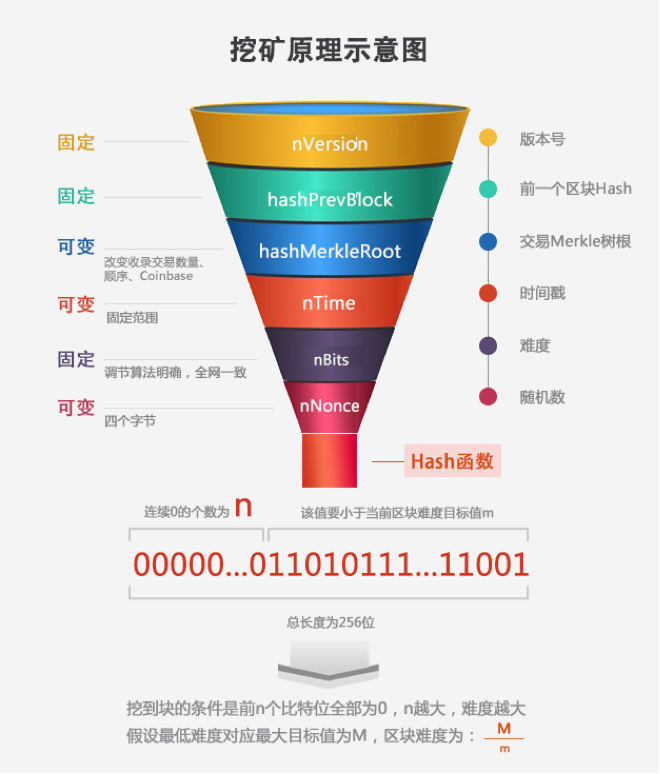
本小节讨论挖矿原理,首先解析比特币区块头(Blockheader)结构,我们说挖矿本质是执行Hash函数的过程,而Hash函数是一个单输入单输出函数,输入数据就是这个区块头。比特币区块头共6个字段:

如上,比特币每一次挖矿就是对这80个字节连续进行两次SHA256运算(SHA256D),运算结果是固定的32字节(二进制256位)。
以上6个字段情况又各不相同,
nVersion,区块版本号,只有在升级时候才会改变。
hashPrevBlock,由前一个区块决定。
nBits,由全网决定,每2016个区块重新调整,调整算法固定。
因此以上3个字段可以理解为是固定的,对于每个矿工来说都一样。矿工可以自由调整的地方是剩下的3个字段,
nNonce,提供2^32种可能取值
nTime,其实本字段能提供的值空间非常有限,因为合理的区块时间有一个范围,这个范围是根据前一个区块时间来定,比前一个区块时间太早或者太超前都会被其他节点拒绝。值得一提的是,后一个区块的区块时间略早于前一个区块时间,这是允许的。一般来说,矿工会直接使用机器当前时间戳。
hashMerkleRoot,理论上提供2^256种可能,本字段的变化来自于对包含进区块的交易进行增删,或改变顺序,或者修改Coinbase交易的输入字段。
根据Hash函数特性,这3个字段中哪怕其中任意1个位的变化,都会导致Hash运行结果巨大变化。在CPU挖矿时代,搜索空间主要由nNonce提供,进入矿机时代,nNonce提供的4个字节已经远远不够,搜索空间转向hashMerkleRoot。
比特币挖矿的逻辑过程如下:
- 打包交易,检索待确认交易内存池,选择包含进区块的交易。矿工可以任意选择,甚至可以不选择(挖空块),因为每一个区块有容量限制(当前是1M),所以矿工也不能无限选择。对于矿工来说,最合理的策略是首先根据手续费对待确认交易集进行排序,然后由高到低尽量纳入最多的交易。
- 构造Coinbase,确定了包含进区块的交易集后,就可以统计本区块手续费总额,结合产出规则,矿工可以计算自己本区块的收益。
- 构造hashMerkleRoot,对所有交易构造Merkle数。
- 填充其他字段,获得完整区块头。
- Hash运算,对区块头进行SHA256D运算。
- 验证结果,如果符合难度,则广播到全网,挖下一个块;不符合难度则根据一定策略改变以上某个字段后再进行Hash运算并验证。
合格的区块条件如下:
SHA256D(Blockherder) < F(nBits)
其中,SHA256D(Blockherder)就是挖矿结果,F(nBits)是难度对应的目标值,两者都是256位,都当成大整数处理,直接对比大小以判断是否符合难度要求。
为了节约区块链存储空间,将256位的目标值通过一定变换无损压缩保存在32位的nBits字段里。具体变换方法为拆分利用nBits的4个字节,第1个字节代表右移的位数,用V1表示,后3个字节记录值,用V3表示,则有:
F(nBits)=V_3 * 2^(8*(V_1-3) )
转载者注:V_3每8位每8位得进行移位,由于当前区块难度目标值,采用小头字节序,越往右移数值越大。
此外难度有最低限制,也就是说 F(nBits) 有个最大值,比特币最低难度取值nBits=0x1d00ffff,对应的最大目标值为:0x00000000FFFF0000000000000000000000000000000000000000000000000000
因此挖矿可以形象的类比抛硬币,好比有256枚硬币,给定编号1,2,3……256,每进行一次Hash运算,就像抛一次硬币,256枚硬币同时抛出,落地后要求编号前n的所有硬币全部正面向上。
SETGENERATE
Setgenerate协议接口代表了CPU挖矿时代。
中本聪在论文里描述了“1 CPU 1 Vote”的理想数字民主理念,在最初版本客户端就附带了挖矿功能,客户端挖矿非常简单,当然,需要同步数据结束才可以挖矿。现在有很多算力很低的山寨币还是直接使用客户端挖矿,有两种方式可以启动挖矿:
在配置文件设置gen=1,然后启动客户端,节点将自行启动挖矿。
客户端启动后,利用RPC接口setgenerate控制挖矿。
如果使用经典QT客户端,点击“帮助”菜单,打开“调试窗口”,在“控制台”输入如下命令:setgenerate true 2,然后回车,客户端就开始挖矿,后面的数字代表挖矿线程数,如果想关闭挖矿,在控制台使用如下命令:setgenerate false,可以使用getmininginfo命令查看挖矿情况。
节点挖矿过程也非常简单:
构造区块,初始化区块头各个字段,计算Hash并验证区块,不合格则nNonce自增,再计算并验证,如此往复。在CPU挖矿时代,nNonce提供的4字节搜索空间完全够用(4字节即4G种可能,单核CPU运算SHA256D算力一般是2M左右),其实nNonce只遍历完两个字节就返回去重构块。
GETWORK
getwork协议代表了GPU挖矿时代,需求主要源于挖矿程序与节点客户端分离,区块链数据与挖矿部件分离。
使用客户端节点直接挖矿,需要同步完整区块链,数据和程序紧密结合,也就是说,如果有多台电脑进行挖矿,需要每台电脑都单独同步一份区块链数据。这其实没有必要,对于矿工来说,最少只需要一个完整节点就可以。而以此同时,GPU挖矿时代的到来,也需要一个协议与客户端节点交互。
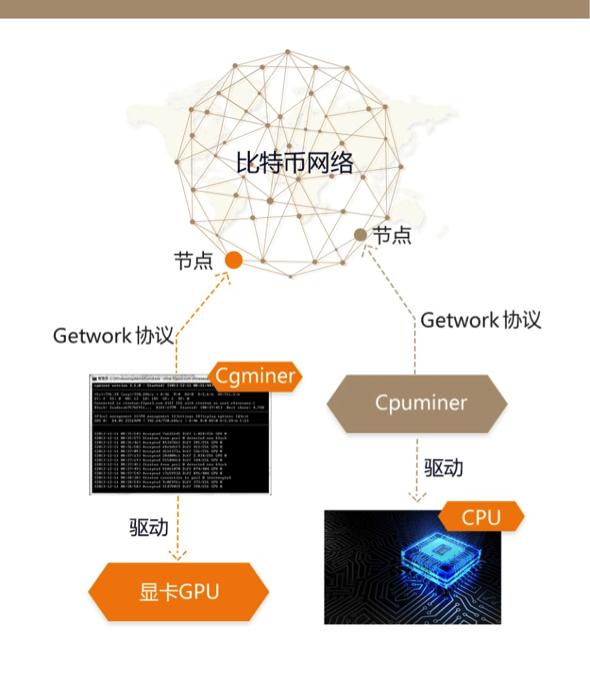
getwork核心设计思路是:
由节点客户端构造区块,然后将区块头数据交给外部挖矿程序,挖矿程序遍历nNonce进行挖矿,验证合格后交付回给节点客户端,节点客户端验证合格后广播到全网。
如前所述,区块头共80个字节,由于没有区块链数据和待确认交易池,nVersion,hashPrevBlock,nBits和hashMerkleRoot这4个字段共72个字节必须由节点客户端提供。挖矿程序主要是递增遍历nNonce,必要时候可以微调nTime字段。
对于显卡GPU来说,其实不用担心nNonce的4字节搜索空间不足,而且挖矿程序从节点客户端那里拿到一份数据后,不应该埋头工作太久,不然很有可能这个块已经被其他人挖到,继续挖只能做无用功,对于比特币来说,虽然设计为每10分钟一个区块,良好的策略也应该在秒级内重新向节点申请新的挖矿数据。对于显卡来说,运行SHA256D算力一般介于200M~1G,nNonce提供4G搜索空间,也就是说再好的显卡也能支撑4秒左右,调整一次nTime,又可以再挖4秒,这个时间绰绰有余。
节点提供RPC接口getwork,该接口有一个可选参数,如果不带参数,就是申请挖矿数据,如果带一个参数,就是提交挖到的块数据。
不带参数调用getwork,返回数据如下:
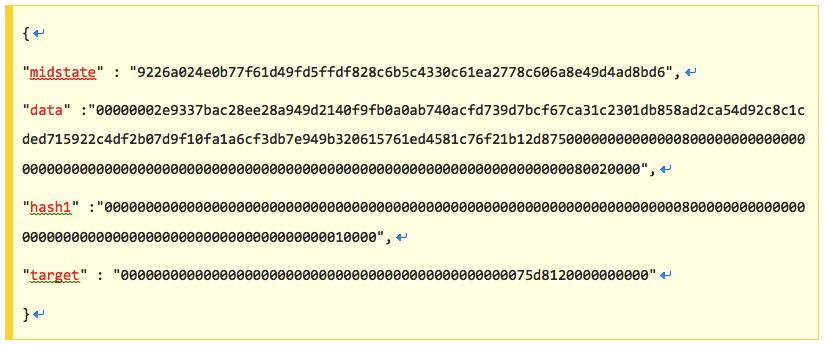
Data字段
共128字节(80区块头字节 + 48补全字节),因为SHA256将输入数据切分成固定长度的分片处理,每个切片64字节,输入总长度必须是64字节的整数倍,输入长度一般不符合要求,则根据一定规则在元数据末端补全数据。其实对于挖矿来说,补全数据是固定不变的,这里没必要提供,外部挖矿软件可以自行补齐。甚至连nNonce字段都不需要提供,data最少只需要提供前面的76字节就够了。nTime字段也是必不可少的,外部挖矿程序需要参照节点提供的区块时间来调节nTime。
Target字段
即当前区块难度目标值,采用小头字节序,需要翻转才能使用。
其实对于外部挖矿程序来说,有data 和 target这两个字段就可以正常挖矿了,不过getwork协议充分考虑各种情况,尽量帮助外部挖矿程序做力所能及的事,提供了两个额外字段,data字段返回完整补全数据也是出于此理念。
Midstate字段
如上所述,SHA256对输入数据分片处理,矿工拿到data数据后,第一个分片(头64字节)是固定不变的,midstate就是第一个分片的计算结果,节点帮忙计算出来了。
因此,在midstate字段辅助下,外部挖矿程序甚至只需要44字节数据就可以正常挖矿:32字节midstate + 第一个切片余下的12(76-64)字节数据。
Hash1字段
比特币挖矿每次都需要连续执行两次SHA256,第一次执行结果32字节,需要再补充32字节数据凑足64字节作为第二次执行SHA256的输入。hash1就是补全数据,同理,hash1也是固定不变的。
外部挖矿程序挖到合格区块后再次调用getwork接口将修改过的data字段提交给节点客户端。节点客户端要求返回的数据也必须是128字节。
每次有外部无参调用一次getwork时,节点客户端构造一个新区块,在返回数据前,都要把新区块完整保存在内存,并用hashMerkleRoot作为唯一标识符,节点使用一个Map来存放所有构造的区块,当下一个块已经被其他人挖到时,立即清空Map。
getwork收到一个参数后,首先从参数提取hashMerkleRoot,在Map中找出之前保存的区块,接着从参数中提取nNonce和nTime填充到区块的对应字段,就可以验证区块了,如果难度符合要求,说明挖到了一个块,节点将其广播到全网。
getwork协议是最早版本挖矿协议,实现了节点和挖矿分离,经典的GPU挖矿驱动cgminer和sgminer,以及cpuminer都是使用getwork协议进行挖矿。getwork + cgminer一直是非常经典的配合,曾经很多新算法推出时,都快速被移植到cgminer。即便现在,除了BTC和LTC,其他众多竞争币都还在使用getwork协议进行挖矿。矿机出现之后,挖矿速度得到极大提高,当前比特币矿机算力已经达到10T/秒级别。而getwork只给外部挖矿程序提供32字节共4G的搜索空间,如果继续使用getwork协议,矿机需要频繁调用RPC接口,这显然不可行。如今BTC和LTC节点都已经禁用getwork协议,转向更新更高效的getblocktemplate协议。
GETBLOCKTEMPLATE
getblocktemplate协议诞生于2012年中叶,此时矿池已经出现。矿池采用getblocktemplate协议与节点客户端交互,采用stratum协议与矿工交互,这是最典型的矿池搭建模式。
与getwork相比,getblocktemplate协议最大的不同点是:getblocktemplate协议让矿工自行构造区块。如此一来,节点和挖矿完全分离。对于getwork来说,区块链是黑暗的,getwork对区块链一无所知,他只知道修改data字段的4个字节。对于getblocktemplate来说,整个区块链是透明的,getblocktemplate掌握区块链上与挖矿有关的所有信息,包括待确认交易池,getblocktemplate可以自己选择包含进区块的交易。
getblocktemplate 在被开发出来后并非一成不变,在随后发行的各个版本客户端都有所升级改动,主要是增添一些字段,不过核心理念和核心字段不变。目前比特币客户端返回数据如下,考虑到篇幅限制,交易字段(transactions)只保留了一笔交易数据,其实根据当前实际情况,待确认交易池实时有上万笔交易,目前区块基本都是塞满的(1M容量限制),加上额外信息,因此每次调用getblocktemplate基本都有1.5M左右返回数据,相对于getwork的几百个字节而言,不可同日而语。

来简单分析一下其中几个核心字段,
Version,Previousblockhash,Bits这三个字段分别指区块版本号,前一个区块Hash,难度,矿工可以直接将数值填充区块头对应字段。
Transactions,交易集合,不但给了每一笔交易的16进制数据,同时给了hash,交易费等信息。
Coinbaseaux,如果有想要写入区块链的信息,放在这个字段,类似中本聪的创世块宣言。
Coinbasevalue,挖下一个块的最大收益值,包括发行新币和交易手续费,如果矿工包含Transactions字段的所有交易,可以直接使用该值作为coinbase输出。
Target,区块难度目标值。
Mintime,指下一个区块时间戳最小值,Curtime指当前时间,这两个时间作为矿工调节nTime字段参考。
Height,下一个区块高度,目前协议规定要将这个值写入coinbase的指定位置。
矿工拿到这些数据之后,挖矿步骤如下:
构建coinbase交易,涉及到字段包括Coinbaseaux,Coinbasevalue,Transactions,Height等,当然最重要的是要指定一个收益地址。
构建hashMerkleRoot,将coinbase放在transactions字段包含的交易列表之前,然后对相邻交易两两进行SHA256D运算,最终可以构造交易的Merkle树。由于coinbase有很多字节可供矿工随意发挥,此外交易列表也可随意调换顺序或者增删,因而hashMerkleRoot值空间几乎可以认为是无限的。其实getblocktemplate协议设计的主要目标就是让矿工获得这个巨大的搜索空间。
构建区块头,利用Version,Previousblockhash,Bits以及Curtime分别填充区块头对应字段,nNonce字段可默认置0。
挖矿,矿工可在由nNonce,nTime,hashMerkleRoot提供的搜索空间里设计自己的挖矿策略。
上交数据,当矿工挖到一个块后当立即使用submitblock接口将区块完整数据提交给节点客户端,由节点客户端验证并广播。
需要注意的是,与上文提到的GPU采用getwork挖矿一样,虽然getblocktemplate给矿工提供了巨大搜索空间,但矿工不应对一份请求数据挖矿太久,而应循环适时向节点索要最新区块和最新交易信息,以提高挖矿收益。
POOL
挖矿有两种方式,一种叫SOLO挖矿,另一种是去矿池挖矿。前文所述的在节点客户端直接启动CPU挖矿,以及依靠getwork+cgminer驱动显卡直接连接节点客户端挖矿,都是SOLO挖矿,SOLO好比自己独资买彩票,不轻易中奖,中奖则收益全部归自己所有。去矿池挖矿好比合买彩票,大家一起出钱,能买一堆彩票,中奖后按出资比率分配收益。理论上,矿机可以借助getblocktemplate协议链接节点客户端SOLO挖矿,但其实早已没有矿工会那么做,在写这篇文章时,比特币全网算力1600P+,而当前最先进的矿机算力10T左右,如此算来,单台矿机SOLO挖到一个块的概率不到16万分之一,矿工(人)投入真金白银购买矿机、交付电费,不会做风险那么高的投资,显然投入矿池抱团挖矿以降低风险,获得稳定收益更加适合。因此矿池的出现是必然,也不可消除,无论是否破坏系统的去中心化原则。
矿池的核心工作是给矿工分配任务,统计工作量并分发收益。矿池将区块难度分成很多难度更小的任务下发给矿工计算,矿工完成一个任务后将工作量提交给矿池,叫提交一个share。假如全网区块难度要求Hash运算结果的前70个比特位都是0,那么矿池给矿工分配的任务可能只要求前30位是0(根据矿工算力调节),矿工完成指定难度任务后上交share,矿池再检测在满足前30位为0的基础上,看看是否碰巧前70位都是0。
矿池会根据每个矿工的算力情况分配不同难度的任务,矿池是如何判断矿工算力大小以分配合适的任务难度呢?调节思路和比特币区块难度一样,矿池需要借助矿工的share率,矿池希望给每个矿工分配的任务都足够让矿工运算一定时间,比如说1秒,如果矿工在一秒之内完成了几次任务,说明矿池当前给到的难度低了,需要调高,反之。如此下来,经过一段时间调节,矿池能给矿工分配合理难度,并计算出矿工的算力。
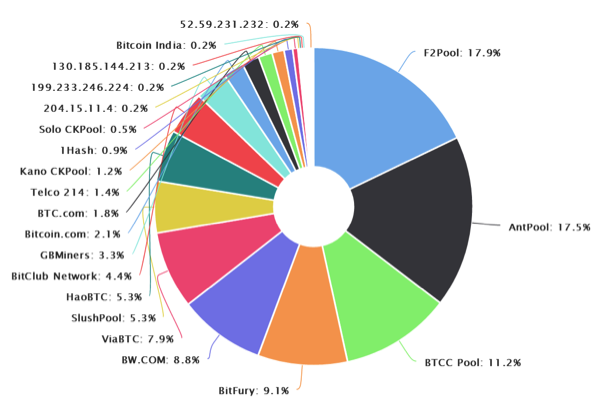
矿池一直都是一个矛盾的存在,毫无疑问,矿池是中心化的,如上图所示,全网算力集中在几个矿池手里,网络虽然几千个节点同时在线,但只有矿池链接的几个点击拥有投票权,其他节点都只能行使监督权。矿池再一次将矿工至于“黑暗”之中,矿工对于区块链再次变得一无所知,他们只知道完成矿池分配的任务。
关于矿池,还有一个小插曲,在矿池刚出现时,反对声特别强烈,很多人悲观的认为矿池最终会导致算力集中,危及系统安全,甚至置比特币于死地。于是有人设计并实现了P2P矿池,力图将“抱团挖矿”去中心化,代码也都是开源的,但由于效率远不如中心化的矿池没能吸引太多算力,所谓理想很丰满,现实很骨感。
推荐几个比较成熟的开源矿池项目,有兴趣的读者可自行研究:
PHP-MPOS,早期非常经典的矿池,很稳定,被使用最多,尤其山寨币矿池,后端使用Stratum Ming协议,源码地址https://github.com/MPOS/php-mpos
node-open-mining-portal,支持多币种挖矿,源码地址https://github.com/zone117x/node-open-mining-portal
Powerpool,支持混合挖矿,源码地址https://github.com/sigwo/powerpool
运行一个矿池需要考虑的问题很多,比如为了得到最及时的全网信息,矿池一般对接几个网络节点,而且最好分布在地球的几大洲。另外提高出块率,降低孤块率,降低空块率等都是矿池的核心技术问题,本文不能一一展开讨论,接下来只详细讨论一个问题,即矿池与矿工的具体配合工作方式——stratum协议。
STRATUM
矿池通过getblocktemplate协议与网络节点交互,以获得区块链的最新信息,通过stratum协议与矿工交互。此外,为了让之前用getwork协议挖矿的软件也可以连接到矿池挖矿,矿池一般也支持getwork协议,通过阶层挖矿代理机制实现(Stratum mining proxy)。须知在矿池刚出现时,显卡挖矿还是主力,getwork用起来非常方便,另外早期的FPGA矿机有些是用getwork实现的,stratum与矿池采用TCP方式通信,数据使用JSON封装格式。
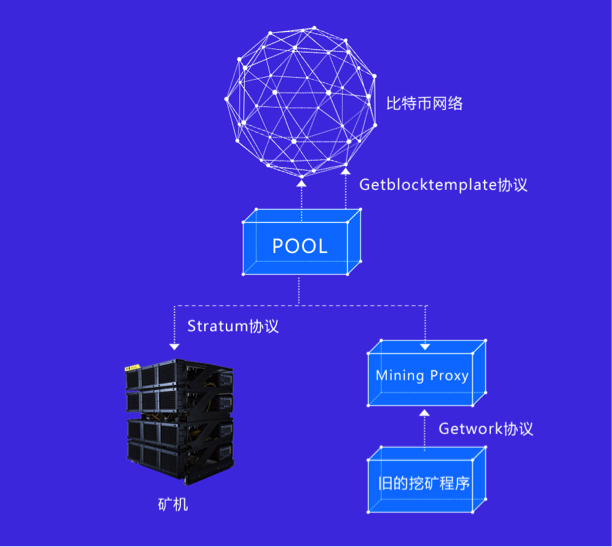
先来说一下getblocktemplate遗留下来的几个问题:
矿工驱动:在getblocktemplate协议里,依然是由矿工主动通过HTTP方式调用RPC接口向节点申请挖矿数据,这就意味着,网络最新区块的变动无法及时告知矿工,造成算力损失。
数据负载:如上所述,如今正常的一次getblocktemplate调用节点都会反馈回1.5M左右的数据,其中主要数据是交易列表,矿工与矿池需频繁交互数据,显然不能每次分配工作都要给矿工附带那么多信息。再者巨大的内存需求将大大影响矿机性能,增加成本。
Stratum协议彻底解决了以上问题。
Stratum协议采用主动分配任务的方式,也就是说,矿池任何时候都可以给矿工指派新任务,对于矿工来说,如果收到矿池指派的新任务,应立即无条件转向新任务;矿工也可以主动跟矿池申请新任务。
现在最核心的问题是如何让矿工获得更大的搜索空间,如果参照getwork协议,仅仅给矿工可以改变nNonce和nTime字段,则交互的数据量很少,但这点搜索空间肯定是不够的。想增加搜索空间,只能在hashMerkleroot下功夫,如果让矿工自己构造coinbase,那么搜索空间的问题将迎刃而解,但代价是必须要把区块包含的所有交易都交给矿工,矿工才能构造交易列表的Merkleroot,这对于矿工来说压力更大,对于矿池带宽要求也更高。
Stratum协议巧妙解决了这个问题,成功实现既可以给矿工增加足够的搜索空间,又只需要交互很少的数据量,这也是Stratum协议最具创新的地方。
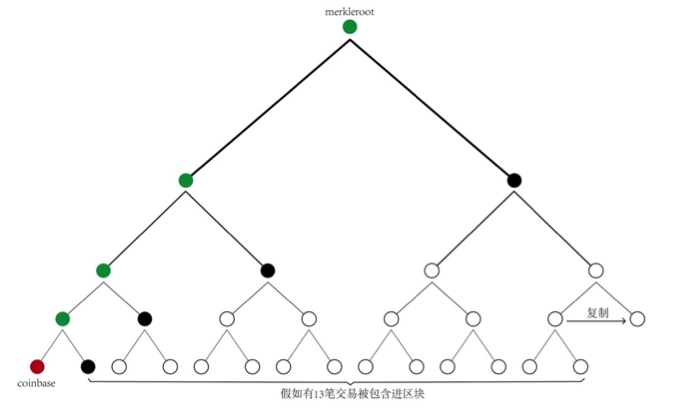
再来回顾一下区块头的6个字段80字节,这个很关键,nVersion,nBits,hashPrevBlock这3个字段是固定的,nNonce,nTime这两个字段是矿工现在就可以改变的。增加搜索空间只能从hashMerkleroot下手,这个绕不过去。Stratum协议让矿工自己构造coinbase交易,coinbase的scriptSig字段有很多字节可以让矿工自由填充,而coinbase的改动意味着hashMerkleroot的改变。从coinbase构造hashMerkleroot无需全部交易,如上图所示,假如区块将包含13笔交易,矿池先对这13笔交易进行处理,最后只要把图中的4个黑点(Hash值)交付给矿工,同时将构造coinbase需要的信息交付给矿工,矿工就可以自己构造hashMerkleroot(图中的绿点都是矿工自行计算获得,两两合并Hash时,规定下一个黑点代表的hash值总是放在右边)。按照这种方式,假如区块包含N笔交易,矿池可以浓缩成log2(N)个hash值交付给矿工,这大大降低了矿池和矿工交互的数据量。
Stratum协议严格规定了矿工和矿池交互的接口数据结构和交互逻辑,具体如下:
1. 矿工订阅任务
启动挖矿机器,使用mining.subscribe方法链接矿池

返回数据很重要,矿工需本地记录,在整个挖矿过程中都用到,其中:
b4b6693b72a50c7116db18d6497cac52:给矿工指定初始难度,
ae6812eb4cd7735a302a8a9dd95cf71f:订阅号ID
08000002:学名Extranonce1 ,用于构造coinbase交易
4:学名Extranonce2_size ,即Extranonce2的长度,这里指定4个字节
Extranonce1,和 Extranonce2对于挖矿很重要,增加的搜索空间就在这里,现在,我们至少有了8个字节的搜索空间,即nNonce的4个字节,以及 Extranonce2的4个字节。
2. 矿池授权
在矿池注册一个账号 ,添加矿工,矿池允许每个账号任意添加矿工数,并取不同名字以区分。矿工使用mining.authorize 方法申请授权,只有被矿池授权的矿工才能收到矿池指派任务。

3. 矿池分配任务
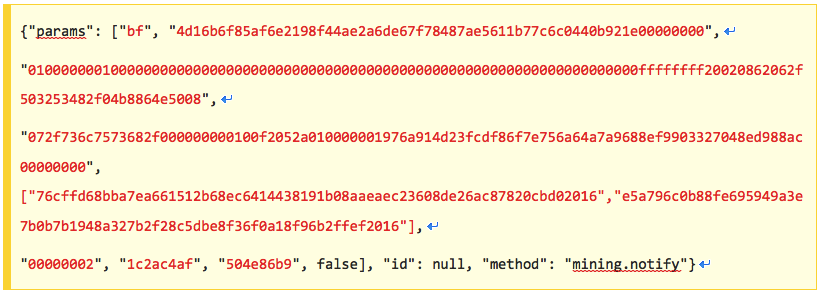
以上每个字段信息都是必不可少,其中:
bf:任务号ID,每一次任务都有唯一标识符
4d16b6f85af6e2198f44ae2a6de67f78487ae5611b77c6c0440b921e00000000:前一个区块hash值,hashPrevBlock
01000000010000000000000000000000000000000000000000000000000000000000000000ffffffff20020862062f503253482f04b8864e5008:学名coinb1 ,构造coinbase的第一部分序列数据
072f736c7573682f000000000100f2052a010000001976a914d23fcdf86f7e756a64a7a9688ef9903327048ed988ac00000000:学名coinb2 ,构造coinbase的第二部分序列数据,
["76cffd68bba7ea661512b68ec6414438191b08aaeaec23608de26ac87820cbd02016","e5a796c0b88fe695949a3e7b0b7b1948a327b2f28c5dbe8f36f0a18f96b2ffef2016"]:学名merkle_branch,交易列表的压缩表示方式,即上图的黑点
00000002:区块版本号,nVersion
1c2ac4af:区块难度nBits
504e86b9:当前时间戳,nTime
有了以上信息,再加上之前拿到的Extranonce1 和Extranonce2_size,就可以挖矿了。
4. 挖矿
构造coinbase交易
用到的信息包括Coinb1, Extranonce1, Extranonce2_size 以及Coinb2,构造很简单:
Coinbase=Coinb1 + Extranonce1 + Extranonce2 + Coinb2
为啥可以这样,因为矿池帮矿工做了很多工作,矿池已经构建了coinbase交易,系列化后在指定位置分割成coinb1和coinb2,coinb1和coinb2包含指定信息,比如coinb1包含区块高度,coinb2包含了矿工的收益地址和收益额等信息,但是这些信息对于矿工来说无关紧要,矿工挖矿的地方只是Extranonce2 的4个字节。另外Extranonce1是矿池写入区块的指定信息,一般来说,每个矿池会写入自己矿池的信息,比如矿池名字或者域名,我们就是根据这个信息统计每个矿池在全网的算力比重。
构建Merkleroot
利用coinbase和merkle_branch,按照上图方式构造hashMerkleroot字段。
构建区块头
填充余下的5个字段,现在,矿工可以在nNonce和Extranonce2 里搜索进行挖矿,如果嫌搜索空间还不够,只要增加Extranonce2_size为多几个字节就可轻而易举解决。
5. 矿工提交工作量
当矿工找到一个符合难度的shares时,提交给矿池,提交的信息量很少,都是必不可少的字段:

slush.miner1:矿工名字,矿池用以识别谁提交的工作量
bf:任务号ID,矿池在分配任务之前,构造了Coinbase等信息,用这个任务号唯一标识
00000001:Extranonce2
504e86ed:nTime字段
b2957c02:nNonce字段
矿池拿到以上5个字段后,首先根据任务号ID找出之前分配任务前存储的信息(主要是构建的coinbase交易以及包含的交易列表等),然后重构区块,再验证shares难度,对于符合难度要求的shares,再检测是否符合全网难度。
6. 矿池给矿工调节难度
矿池记录每个矿工的难度,并根据shares率不断调节以指定合适难度。矿池可以随时通过mining.set_difficulty方法给矿工发消息另其改变难度。

如上,Stratum协议核心理念基本解析清楚,在getblocktemplate协议和Stratum协议的配合下,矿池终于可以大声的对矿工说,让算力来的更猛烈些吧。
AUXPOW
在挖矿的发展历史上,还出现了一个天马行空的事情,即混合挖矿(Merge Mining)。域名币(Namecoin)最先使用混合挖矿模式,挂靠在比特币链条上,矿工挖比特币时,可以同时挖域名币,后来狗狗币(Dogecoin)也支持混合挖矿,挂靠在莱特币(Litecoin)链条上。混合挖矿使用Auxiliary Proof-of-Work (AuxPOW)协议实现,虽然混合挖矿不怎么流行,但是协议设计的很精巧,最初看到协议时我不禁感叹社区的力量之伟大,这种都能想出来。
以域名币的混合挖矿举例,比特币作为父链(Parent Blockchain),域名币作为辅链(Auxiliary Blockchain),AuxPOW协议的实现无需改动父链(比特币当然不会为了域名币做任何改动),但辅链需要做针对性设计,比如狗狗币改为支持混合挖矿时就进行了硬分叉。
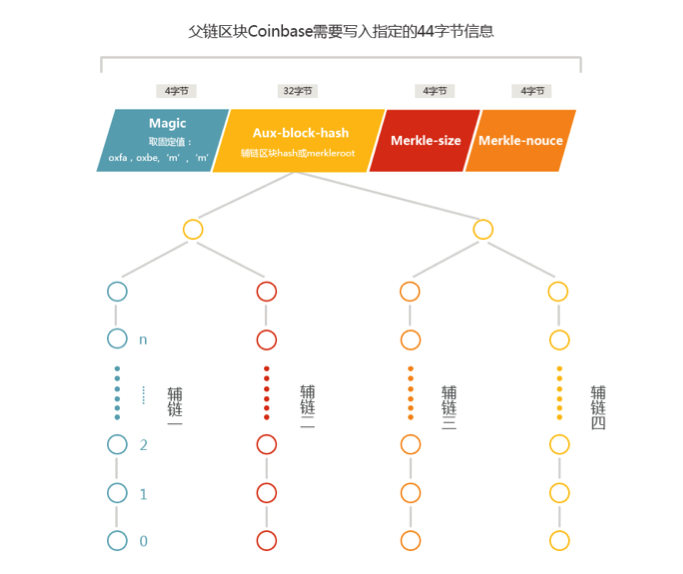
AuxPOW的实现得益于比特币Coinbase的输入字段,中本聪当初不知有意无意,在此处只规定了长度限制,留了一片未定义区域。这片区域后来对比特币的发展产生深远影响,很多升级和优化都盯上这片区域,比如上文讲的Stratum协议。中本聪类似的有意无意情况还有很多,比如交易的nSequence字段,也是因为没有明确定义,被黑客盯上引发的“延展性”问题成了“门头沟”倒闭的替罪羊。再比如说nNonce,如果一开始定义的字节大一些,你比方说32字节,挖矿的演进就不需要以上讨论的那么多协议。
AuxPOW协议核心理念不同的地方在于:
对于经典的POW区块,规定只有难度符合要求才算一个合格的区块,AuxPOW协议对区块难度没有要求,但附加两个条件:
- 辅链区块的hash值必须内置于父链区块的Coinbase里。
- 该父链区块的难度必须符合辅链的难度要求。
将辅链区块的hash值内置于父链的Coinbase,其实是利用父链作存在证明。这样就可以实现间接依靠父链的算力来维护辅链安全。一般来说,父链的算力比辅链大,因而满足父链难度要求的区块一定同时满足辅链难度要求,反之则不成立。这样一来,很多本来在父链达不到难度要求的区块,却达到辅链难度要求,矿工g=广播到辅链网络,在辅链获得收益,何乐而不为。
AuxPOW协议对两条链都有一些数据结构方面的规定,对于父链,要求必须在区块的coinbase的scriptSig字段中插入如下格式的44字节数据:
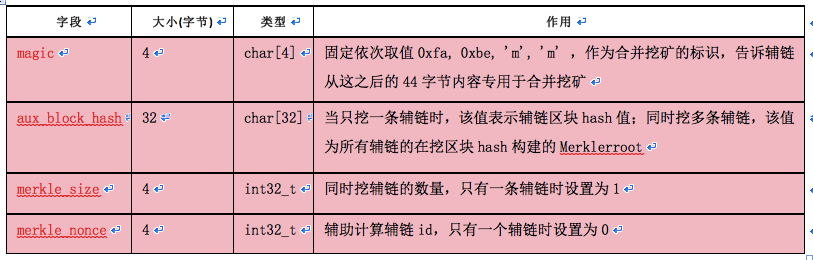
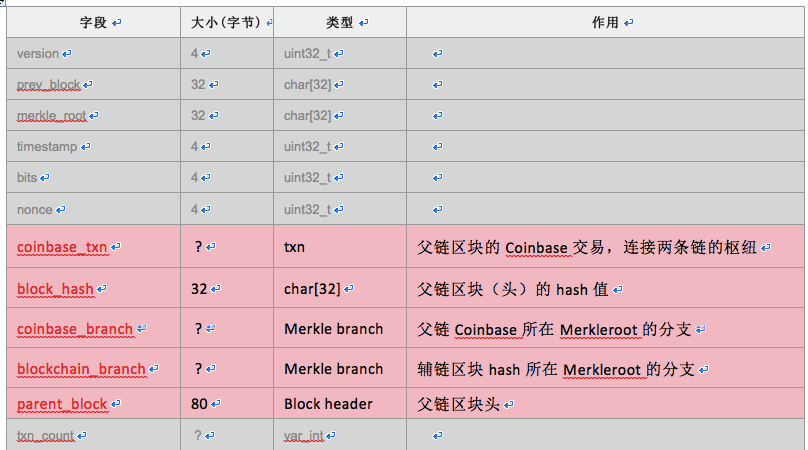
对于辅链,对原区块结构改动比较大,在nNonce字段和txn_count之间插入了5个字段,这种区块取名AuxPOW区块。
混合挖矿要求父链和辅链的算法一致,是否支持混合挖矿是矿池的决定,矿工不知道是否在混合挖矿。矿池如果支持混合挖矿,需要对接所有辅链的节点。
将辅链区块hash值内置在父链的Coinbase,意味着矿工在构造父链Coinbase之前,必先构造辅链的AuxPOW 区块并计算hash值。如果只挖一条辅链,情况较为简单,如果同时挖多条辅链,则先对所有辅链在挖区块构造Merkleroot。矿池可以将特定的44字节信息内置于上文Stratum协议中提到的Coinb1中,交给矿工挖矿。对矿工返回的shares重构父链区块和所有辅链区块,并检测难度,如果符合辅链难度要求,则将整个AuxPOW区块广播到辅链。
辅链节点验证AuxPOW区块逻辑过程如下:
- 依靠父链区块头(parent_block)和区块Hash值(block_hash,本字段其实没必要,因为节点可以自行计算),验证父链区块头是否符合辅链难度要求。
- 依靠Coinbase交易(coinbase_txn)、其所在的分支(coinbase_branch)以及父链区块头(parent_block),验证Coinbase交易是否真的被包含在父链区块中。
- 依靠辅链分支(blockchain_branch),以及Coinbase中放Hash值的地方(aux_block_hash),验证辅链区块Hash是否内置于父链区块的Coinbase交易中。
通过以上3点验证,则视为合格的辅链区块。
CONCLUSION
中本聪最初设计比特币时希望所有节点都采用CPU挖矿,一般认为只有这样才能充分保证区块链的去中心化特征,比特币在CPU时代安全度过了萌芽阶段。getwork和cgminer将挖矿带入GPU时代,国内显卡曾经一度脱销,全网算力迅速提升了一个档次,CPU挖矿惨遭淘汰。随着越来越多人参与挖矿,全网算力不断上升,催生了抱团挖矿(矿池)。然而GPU时代的繁荣历史也没能持续多久就被getblocktemplate,stratum以及矿机带入了ASIC时代。
getwork实现了数据与挖矿分离,getblocktemplate给外部挖矿程序提供了最大自由度,彻底解决了外部挖矿程序与节点交互的可扩展性问题(scalability problems),主要用于矿池与网络节点对接。stratum不但解决了搜索空间不足的问题,同时也解决了矿池与矿机交互数据量大的问题。getblocktemplate和stratum这两个协议使大型矿池,大规模矿场,大算力矿机成为可能,从此挖矿产业进入一个全新阶段,此后挖矿的演进主要集中于几个方向:矿池的设计优化与稳定运行,矿场的科学部署,以及矿机工艺升级,提升算力,降低功耗等。