作者:知识天地
时间:2018年1月14日
来源:https://www.cnblogs.com/mfryf/p/8284801.html
之前的章节已经比较粗略的解释了在Transaction体系当中的整体运作原理。接下来的章节会对这个体系进行分解,比较详细描述细节的构成。
本章将要详细分析bitcoin交易中的交易脚本-script到底是什么东西。
回顾和概要
在前面的文章中提到,在bitcoin的体系中,一个交易是被发布到比特币的整体系统中的,而能够操控之前交易的的TxOut(被锁住的coin),是需要能够操控这个TxOut的人提供”钥匙”来控制。就像前文描述的,coin在整个系统中是像流水一样的在体系中进行流通,而coin在其中在分叉点的时候会有一个像 “锁” 的东西把coin锁在这个节点上。而根据这个锁产生了一个新的交易,继续流通被这个锁所锁住的coin,是需要提供一个”钥匙”的。
所以这里的比喻:“锁”和“钥匙”就是比特币交易中的交易脚本Script
其中
“锁” 对应着 scriptPubKey
“钥匙”对应着 scriptSig
但是单纯的把Script理解为“锁”和“钥匙”实在是太浅薄了。只能完成这点事情的并不能体现Script 的强大,也无法对后人创立“智能合约”有所启发。
所以在我看来,比特币的Script实际上是:
scriptPubKey 是上一个交易(out)提出的一个 “问题”
而
scriptSig 是我想使用上一个交易中的钱,那么我就对你提出的这个问题提供我的“答案”
因为公私钥的关系,所以如果scriptPubKey 提出的问题是公钥相关的问题,那么很明显,只有持有私钥的人才能回答这个问题,所以就简化为刚才的所说的“锁”和“钥匙”的关系。
而另一方面,如何确认提供的“答案”就是能回答“问题”的呢?这就说明Script是需要被执行验证的,而且这个验证的过程只需要txin提供的scriptSig 和验证者自己从自己的记录中找到的txout的scriptPubKey ,而这个验证者就是广大的矿工们。
整个系统精妙的地方就在于,scriptPubKey是验证者(矿工)各自独立持有的东西,其安全性由自己所保证的,而想要完成交易的人只需要提供scriptSig给广大验证者就行,不需要一些多余的上下文(可以理解为上下文由验证者自己持有,虽然大家都互不信任,但是对于最广大的人来说,这个上下文都是相同的)。
另一个方面不太被大多数人所注意到的是:
实际上刚才的模型简化为了“问题”和“答案”,但是这个“问题”可不是很容易提供的。
这个“问题”应该满足2个方面的要求:
- 问题的答案必须是十分明确的,唯一的,不能是个模糊的要求(这点在代码中就是“代码就是法律”的体现吧(笑),或许这就是智能合约无法完成真正人们所向往的替代所有合同执行的原因,因为合同虽然签订了,但是其中的内容其实很多是有讨价划价,钻空子的空间的)
- 答案必须容易的被验证而不需要其他上下文环境。(这点就是这个问题提出的困难的地方,也就是这个问题要么正向很难,逆向很容易,要么验证需要提供其他的附加的上下文环境。)
而公私密钥的模式其实是完美的符合了这2方面的要求的。
那么有没有其他的问题呢?那是当然有的,比如我提出了一个数学问题,这个问题的解是唯一的并且可以很容易的验证我的回答对不对
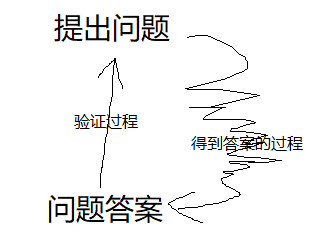
那么我就可以创建一笔交易,而这笔交易的txin就提供这个问题的答案,只要我的这个tx优先被矿工打包进入区块中,并成为最长链,那么这个问题下的钱就归我了。
这个场景就是符合正向很难,逆向容易的场景。
接下来就解释 比特币系统中的 CScript 到底是怎么运作的。
CScript
在比特币源码当中,对于CScript 单独列出了 script.c/script.h 来实现这块体系(对比把tx,block等所有实现全部放在main.c/.h来说),可见得中本聪在一开始设计这套体系的时候就把这块的内容看的相当的重要。事实上这套体系也确实很复杂,但是也是得益于这套体系,才能取得现在的地位,如果没有这个设计,比特币的实用性会被大幅度减弱。
class CScript : public vector<unsigned char>
{
// 把各种类型的数据序列化到 vector 中
CScript& operator<<(char b) { return (push_int64(b)); }
CScript& operator<<(short b) { return (push_int64(b)); }
CScript& operator<<(int b) { return (push_int64(b)); }
CScript& operator<<(long b) { return (push_int64(b)); }
CScript& operator<<(int64 b) { return (push_int64(b)); }
CScript& operator<<(unsigned char b) { return (push_uint64(b)); }
CScript& operator<<(unsigned int b) { return (push_uint64(b)); }
CScript& operator<<(unsigned short b) { return (push_uint64(b)); }
CScript& operator<<(unsigned long b) { return (push_uint64(b)); }
CScript& operator<<(uint64 b) { return (push_uint64(b)); }
CScript& operator<<(opcodetype opcode)
CScript& operator<<(const uint160& b)
CScript& operator<<(const uint256& b)
CScript& operator<<(const CBigNum& b)
CScript& operator<<(const vector<unsigned char>& b)
{
//
}
bool GetOp(const_iterator& pc, opcodetype& opcodeRet, vector<unsigned char>& vchRet) const
{
// ....
}
void FindAndDelete(const CScript& b)
{
// ...
}
};
从这个类中可以看到,其实CScript其实就是vector<char> ,没什么特别的,重要的不是它是什么,重要的是它的内容是什么,会起什么作用。
可以看出其实这类的作用,是像提供了一个容器,这个容器可以存储其他类型的数据(基本类型,uint64,uint256,uint160…),换句话说,这是提供了一个容器来接受各种数据类型的序列化。但是除了基本属性之外,对于Script,定义了一个特别的东西,就是opcodetype,也就是操作符。而类中的GetOp()方法显然就是从vector<char>这样的“流”式数据中把操作符从其中识别出来的方法。
所以从这里可以一窥Script的真实作用,它是由一系列操作符和数据组合而成的,由操作符持有逻辑(动作),由数据持有”状态”的结构体,因为它最终是被传输和存储的,所以使用vector<char>作为容器,将操作符和数据“序列化”到了这个容器中。
Script的操作符
对于CScript中持有的关于“操作符”相关的是opcodetype。
这个操作符实际上就是一个枚举类型,如果把Script当作语言相关的概念,那么实际上opcode就是对应类似汇编中的指令。所以指令的行为是由人制定的,那么指令的表示实际上就是一个代号。下面这个枚举类型就是源码中的opcodetype,做了一些删减。
enum opcodetype
{
// push value 这部分的指令相当于表示这个指令后面的数据是怎么样的组织性质,
OP_0=0,
OP_FALSE=OP_0,
OP_PUSHDATA1=76, // 0x4c 为什么是这个值其实我不太清楚,不过可以肯定的是,这个值是76那么 OP_1 就是81 也就是0x51
OP_PUSHDATA2,
OP_PUSHDATA4,
OP_1NEGATE,
OP_RESERVED, // 80
OP_1, // 81 也就是 0x51,但是为什么要求这个值是81不太清楚,但是感觉很特别
OP_TRUE=OP_1, // 81
OP_2,
OP_3,
//... 一直到Op_16
// control // 以下是控制流指令,比如 if 这类的指令,就是作为控制流存在的了
OP_NOP,
OP_VER,
OP_IF,
OP_NOTIF,
OP_VERIF,
OP_VERNOTIF,
OP_ELSE,
OP_ENDIF,
OP_VERIFY,
OP_RETURN,
// stack ops // 以下是对于栈的操作,这里可以理解为,栈用来保存了数据当前所处于的状态,
// 这些指令相当于控制栈当前的状态,可以比作在编程中对当前操作对象的把控?。下文会对整体流程进行讲解
OP_TOALTSTACK,
OP_FROMALTSTACK,
OP_2DROP,
OP_2DUP,
OP_3DUP,
OP_2OVER,
// ...
// splice ops // 这些也是对数据的一些处理操作,但是这些是对栈中数据本身的内容进行操作
OP_CAT,
OP_SUBSTR,
OP_LEFT,
OP_RIGHT,
OP_SIZE,
// bit logic // 这个和上者一样,不过是位操作
OP_INVERT,
OP_AND,
OP_OR,
OP_XOR,
// ...
// numeric // 这个和上者一样,不过是数字逻辑操作
OP_1ADD,
OP_1SUB,
OP_2MUL,
OP_2DIV,
OP_NEGATE,
OP_ABS,
OP_NOT,
OP_0NOTEQUAL,
OP_ADD,
OP_SUB,
OP_MUL,
OP_DIV,
//...
// crypto // 这个和上者一样,但是操作的是和hash加密等相关的内容,可以理解为对bitcoin系统的特有的DSL
OP_RIPEMD160,
OP_SHA1,
OP_SHA256,
OP_HASH160,
OP_HASH256,
OP_CODESEPARATOR,
OP_CHECKSIG, // 这个是用的最多的,就是来判定签名是否符合的指令
OP_CHECKSIGVERIFY,
OP_CHECKMULTISIG,
OP_CHECKMULTISIGVERIFY,
// multi-byte opcodes
OP_SINGLEBYTE_END = 0xF0,
OP_DOUBLEBYTE_BEGIN = 0xF000,
// template matching params // 下面这两个代表bitcoin特别的数据结构,公钥(地址)
OP_PUBKEY,
OP_PUBKEYHASH,
OP_INVALIDOPCODE = 0xFFFF,
};
可以看到这些指令其实都是很清晰的,只不过这些指令运行的方式有点接近汇编指令的运作方式,(c语言的栈)接下来会举例如何运行Script。
Script 运行方式
这里有一篇比较好的文章介绍了它的运行:
这里我详细介绍一下:
首先明确整体脚本的运行时基于栈运行的,而刚才上一章介绍的指令就是操作栈中元素的方式。
- OP_DUP:复制栈顶元素
这里借用一下刚才那个链接里面的图。

在源码中呢,执行Script的函数是EvalScript()
而整体的运行流程就是 (script.cpp)
- 传入脚本Script(这个脚本是把 scriptPubKey 和 scriptSig) 拼接在一起的一个总的Script
bool VerifySignature(const CTransaction& txFrom, const CTransaction& txTo, unsigned int nIn, int nHashType)
{
// ...
// 注意这里把 txin 的 scriptSig 和 txout 的 scriptPubKey 拼接在一起
return EvalScript(txin.scriptSig + CScript(OP_CODESEPARATOR) + txout.scriptPubKey, txTo, nIn, nHashType);
}
2. 创建一个 stack(栈),这个stack就是前文一直提到的栈。但是这个栈说穿了就是一个vector,就是数据结构里的那个东西
bool EvalScript(const CScript& script, const CTransaction& txTo, unsigned int nIn, int nHashType,
vector<vector<unsigned char> >* pvStackRet)
{
CAutoBN_CTX pctx;
CScript::const_iterator pc = script.begin();
CScript::const_iterator pend = script.end();
CScript::const_iterator pbegincodehash = script.begin();
vector<bool> vfExec; // 这个是暂时记录 栈中执行if判断结果的地方
vector<valtype> stack; // 栈就是这个,而valtype是一个定义 typedef vector<unsigned char> valtype;
// ...
}
3. 整个的执行过程就是,首先执行了 scriptSig,那么这个scriptSig就会在栈中留下一系列的状态和数据,而这些状态和数据是为了配对scriptSig中的状态和数据(也就是为了配对问题的答案)。读取(并执行,虽然对于scriptSig应该大部分都是提供数据,不会带有执行过程)scriptSig后,那么就开始读取scriptPubKey,每读取scriptPubKey中的一个操作符,就执行一次。可以把其当作解释形语言的形式,读取一条执行一条。
例如以源码中的最基础交易模板为例:
bool Solver(const CScript& scriptPubKey, vector<pair<opcodetype, valtype> >& vSolutionRet) // script.cpp
{
// Templates
static vector<CScript> vTemplates;
if (vTemplates.empty())
{
// Standard tx, sender provides pubkey, receiver adds signature
vTemplates.push_back(CScript() << OP_PUBKEY << OP_CHECKSIG);// Short account number tx, sender provides hash of pubkey, receiver provides signature and pubkey
vTemplates.push_back(CScript() << OP_DUP << OP_HASH160 << OP_PUBKEYHASH << OP_EQUALVERIFY << OP_CHECKSIG);
}
// ....
}
// 我们以bitcoin提供的 vTemplates 中的第二个为例:
// 以下是出现相关代码的地方:
void CSendDialog::OnButtonSend(wxCommandEvent& event){ //ui.cpp
//...
if (fBitcoinAddress)
{
// Send to bitcoin address
CScript scriptPubKey;
scriptPubKey << OP_DUP << OP_HASH160 << hash160 << OP_EQUALVERIFY << OP_CHECKSIG; // 这里对应的就是第二个模板 hash160是收款方地址
//...
}
// 生成对于这个脚本配对的 scriptSig 位于 Solver 内
bool Solver(const CScript& scriptPubKey, uint256 hash, int nHashType, CScript& scriptSigRet)
{
else if (item.first == OP_PUBKEYHASH) // 这里对应的是第二个模板,注意 OP_PUBKEYHASH
{
// Sign and give pubkey
// ...
if (hash != 0)
{
vector<unsigned char> vchSig;
if (!CKey::Sign(mapKeys[vchPubKey], hash, vchSig))
return false;
vchSig.push_back((unsigned char)nHashType);
scriptSigRet << vchSig << vchPubKey; // 除了 sig 外 还要把 pubkey 也添加进入scriptsig中 // 这里就是生成答案的地方
}
// ...
所以对于整个执行过程就是这样的:
首先对于
vector stack;来说,从 scriptSig 中压栈 vchSig 和 vchPubkey。那么栈中就拥有了 vchSig,vchPubkey。那么接下来的执行过程如下:
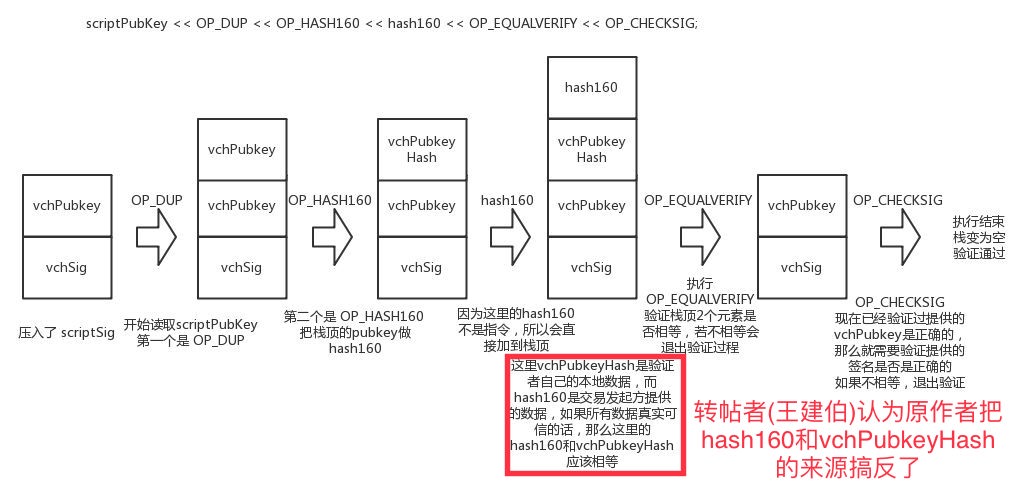
整体的过程就是这样的。就相当于一个人提供的答案,然后验证者拿出这份答案对应的问题,然后看一眼问题,检查一下问题的结果,然后再看问题,再执行,依次执行下去的过程。
所以如果问题不是公私钥配对解密,而是其他的问题,比如创建一个
pubkey<< 100 << 200 << OP_1ADD << OP_EQUALVERIFY
的问题,那么对应这个问题的答案就显然是
就是这样的过程。
其他
以上详细的介绍了整个脚本的运作流程。现在指明一些细节:
- 数据类的序列化(<<操作符)进入脚本都会被 OP_PUSHDATA1,OP_PUSHDATA2,OP_PUSHDATA4 操作符所标明,指明这是一个数据
- 在序列化数据的时候,注意数字 1-16 和 -1 会被认为是操作符OP_1-OP_16和OP_1NEGATE。我目前尚不清楚为何需要这样设计,或许是保留字段?
class CScript : public vector<unsigned char>
{
protected:
CScript& push_int64(int64 n)
{
if (n == -1 || (n >= 1 && n <= 16))//注意这里!
{
push_back(n + (OP_1 - 1)); // 对1-16产生了OP_1的偏移(OP_1=81)
}
else
{
CBigNum bn(n);
*this << bn.getvch();
}
return (*this);
}
string ToString() const
{
//...
while (GetOp(it, opcode, vch))
{
if (!str.empty())
str += " ";
if (opcode <= OP_PUSHDATA4)
str += ValueString(vch);
else
str += GetOpName(opcode); // 1-16, -1 最后会进入这个分支
}
return str;
}
}
总结
Script是比特币系统中异常强大的地方,真是这种运作模式开启了之后的智能合约的风潮。
其把简单的认证一个交易的归属问题的流程从简单的认证扩展到脚本的运行,粗略来看是把一个简单的东西变得复杂了,实际上是极大的扩展了“交易”的含义。使得交易可以含有“逻辑”,而不仅仅是“状态”
中本聪把 “交易过程” 开创性的演化为了 “问题-答案” 的过程,重新定义了什么是“交易”
另一方面正如许多人所说的,在整个指令集中没有出现循环指令,所以这个指令集不是一个图灵完备的语言,它只能按照脚本的编写顺序执行。至于为什么会这样设计?有人猜测说是中本聪认为脚本的执行不应该出现循环,否则要是有人写了死循环恶意破坏会造成很大麻烦,有人认为在这种模式下图灵完备是没有必要的,有人认为对于“交易合同”来说这些已经足够了,有人认为是中本聪没有考虑好这个问题。不管怎么说,交易的脚本绝对是使比特币成为强大功能系统中不可缺少的一环。
所以后来的以太坊正是完成了中本聪最后没有完成的这个东西,成为了拥有“智能合约”能力的区块链,向去中心化理想国迈进新的一步。